
目次
年末年始に掛けてビットコインが話題だったので自動売買に挑戦してみました。
大まかに以下の流れで売買アルゴリズムを作成していきました。
①模擬の取引結果ログをDWHに溜める
②BIツールで結果を可視化・分析
③分析結果を踏まえて売買アルゴリズムを改良
その結果、本番運用に至る前に利益が出そうにないと判断してやめました。
なので、作ったものの供養的な意味を込めて記事を書いています。
そんな訳で、「こうやったら儲かった」的な話はありません。儲かる「売買アルゴリズム」の話でもありません。
主に技術的な構成の話(特にDWHとBI周り)になります。
それでは見ていきましょう。まずは全体の構成になります。
システムの構成について
全体の構成は大まかに以下のとおりです。
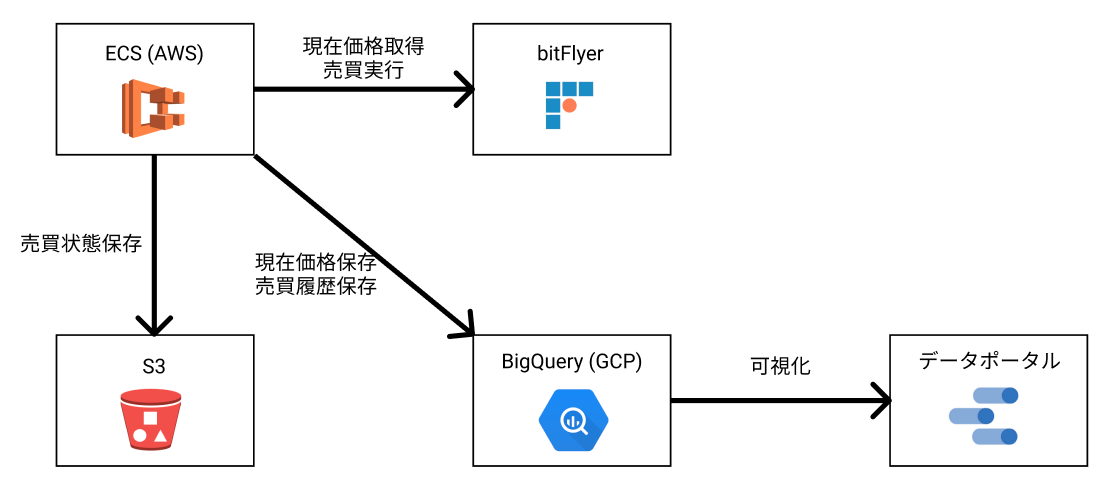
処理はECS上で実行しており、bitFlyer, S3, BigQueryの間を繋ぐ形で価格の取得や売買判断を行っています。
処理は大きく分けて以下の2種類あります。
- 価格取得プロセス
- 売買プロセス
それぞれ詳しく見ていきます。
価格取得プロセス
定期的に現在価格を取得してBigQueryに登録するだけのプロセスです。
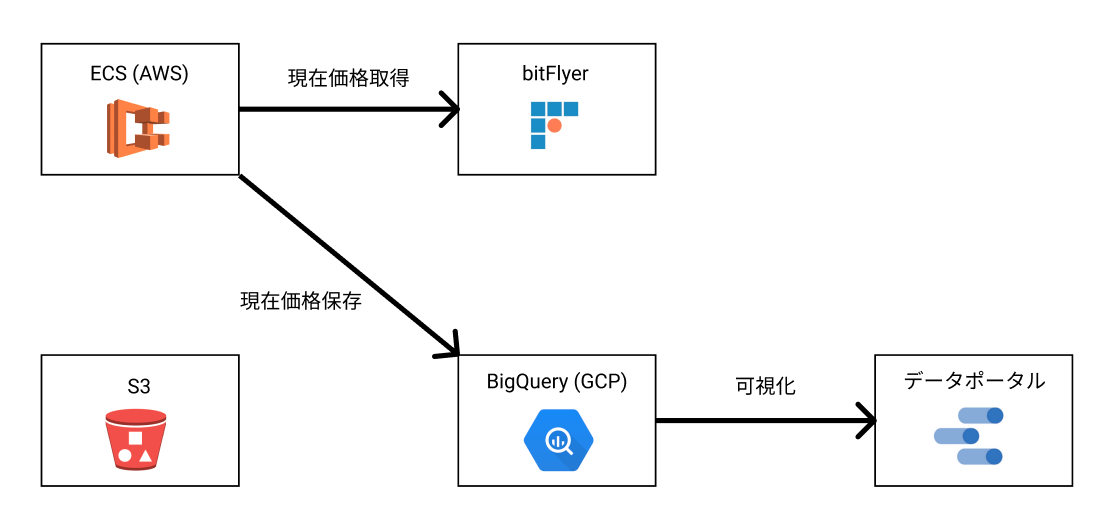
価格を一度BigQueryに入れる事で、これまでの価格の推移から売買タイミングを判断できるようにしています。
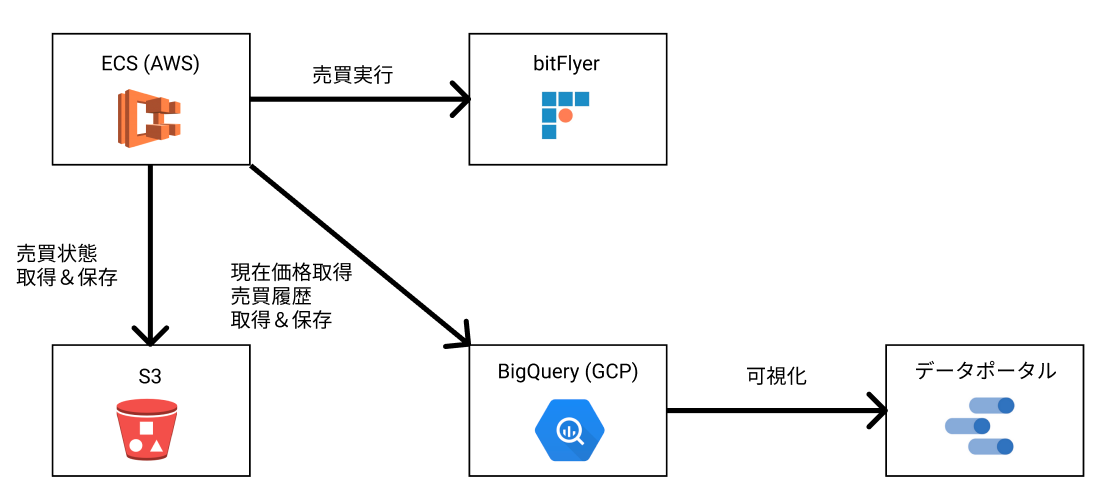
売買プロセス
定期的にBigQueryから価格の推移を取り出して、売買判断を行い、売買を行うプロセスです。
売買を行った際は結果をBigQueryに保存したりもします。
各プロセスの実装について
Nodeで実装しDockerコンテナとしてECSにデプロイされています。
それほど難しい処理はありませんが、以下だけ気をつけて実装しました。
- 複数のアルゴリズムの組み合わせを同時実行できるようにする
- 副作用を伴う処理をInfrastructure層に切り出す(ユニットテストを書きやすくするため)
続いて、各構成要素について説明していきます。
BitFlyerについて

BitFlyerは仮想通貨の取引所です。
取引を行うためのAPIを提供しており、このAPIを通して、仮想通貨の価格情報を取得したり、売買を行っていました。
APIのドキュメント
BigQueryについて

BigQueryはGCPのサービスの1つで、検索と挿入に強いマネージドなデータウェアハウスです。
検索を分散処理する事で大量のデータに対しても高速に結果を返します。
また、一般的なRDBの様にSQLで検索できます。
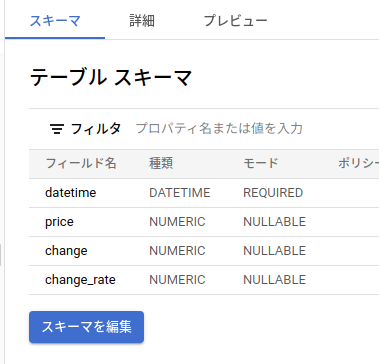
今回は仮想通貨の価格や、取引履歴をBigQueryに保存していました。
公式ドキュメント
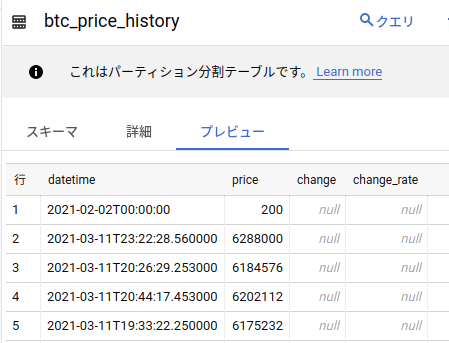
データの可視化について

データポータルはGoogleのBIサービスの1つで、BigQueryのデータを簡単に可視化できます。
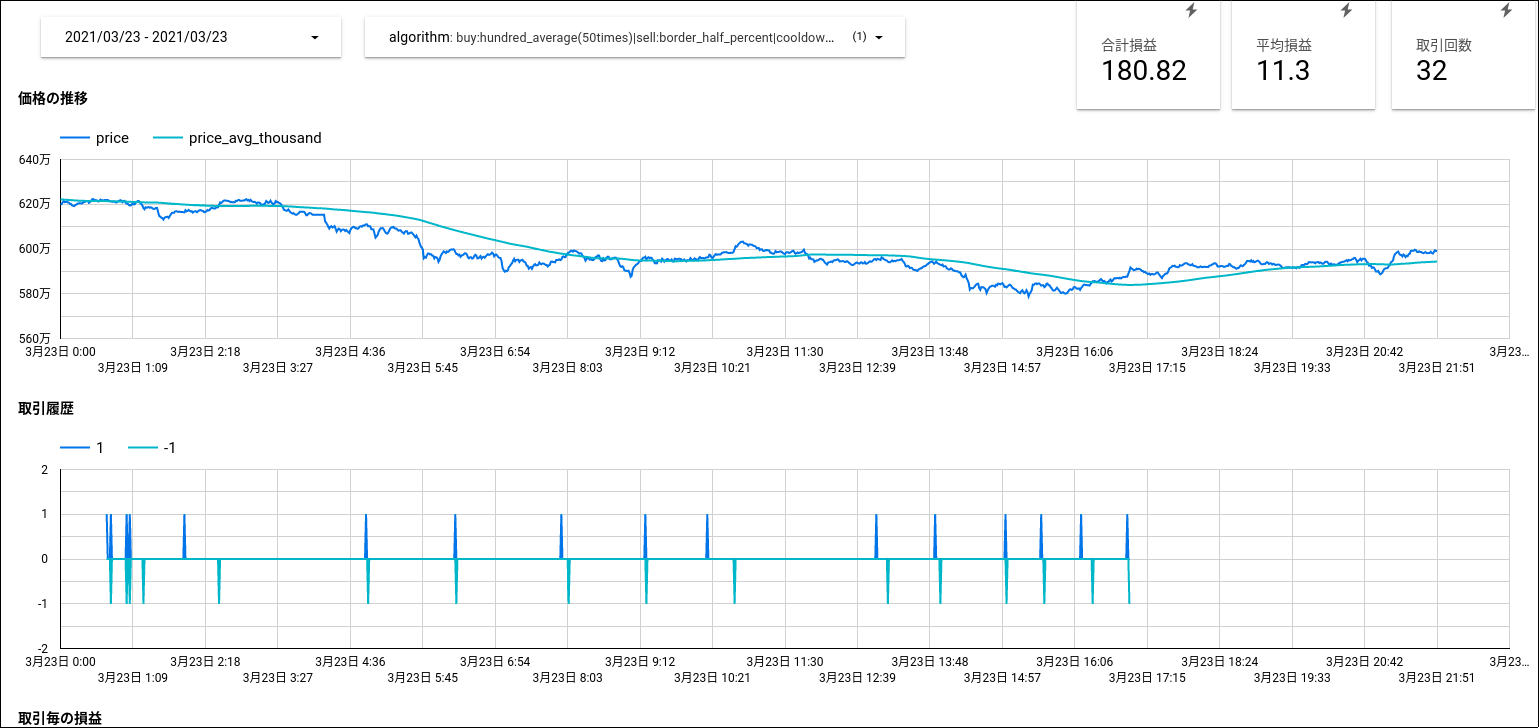
今回は「価格の推移」「取引の履歴」「合計損益」「平均損益」といった数値をデータポータルでグラフ化してアルゴリズムの調整に活用していました。
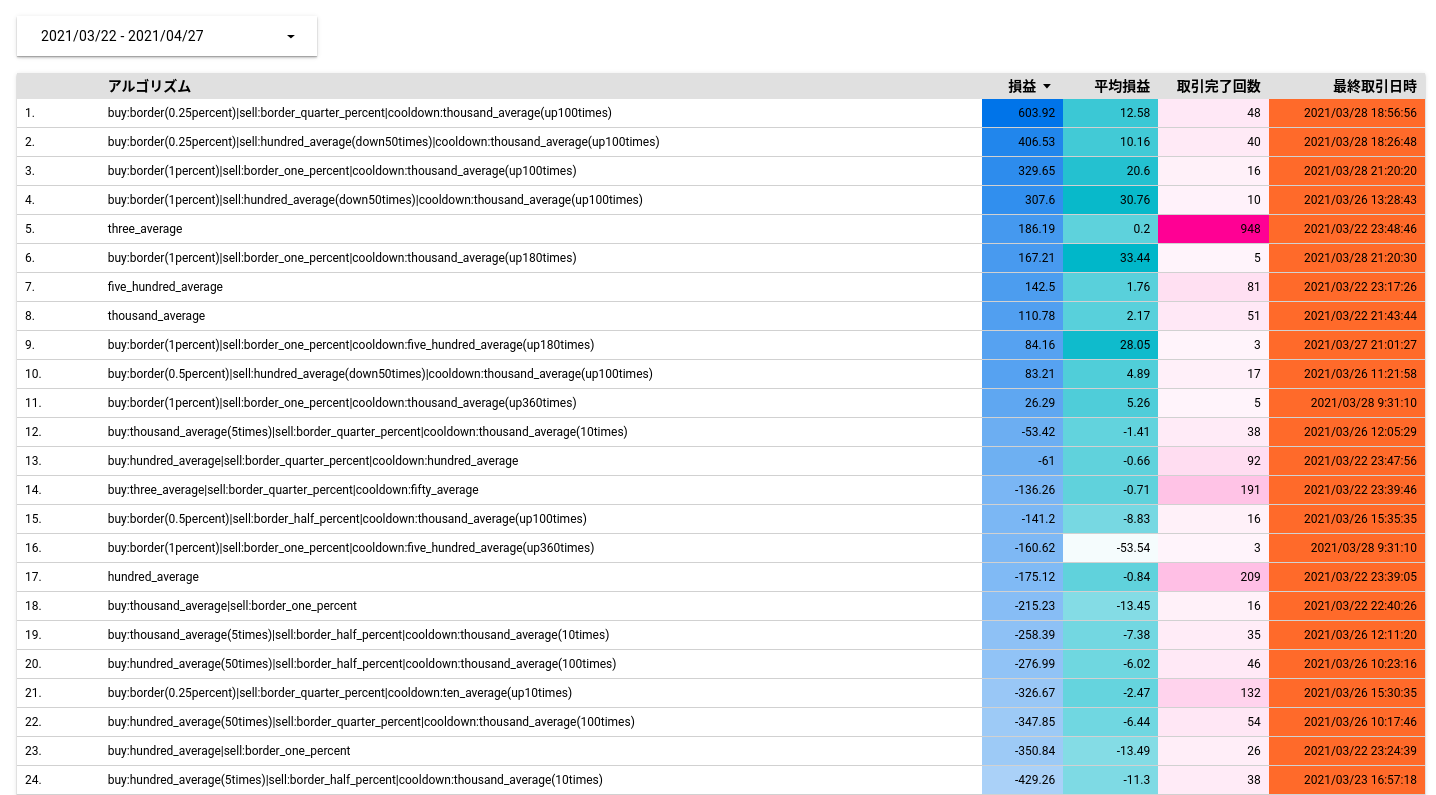
以下のように、アルゴリズム毎の成績を一覧化して、成績の良いアルゴリズムを探しました。
構成要素の説明は以上になります。
自動売買に関する結論
上記の構成でデータを取りつつ、利益が出せそうなアルゴリズムを探りました。
結論として価格の推移を元に判断を行う自動売買で利益を出すのは難しいと感じました。
取引を重ねるほど平均損益は0に近づき、手数料分だけ損するような結果になりました。
実際にはインフラの維持費もあるので黒字にするのはかなり難しいと思います。
売買アルゴリズムについて
購入、売却の判断について、いくつかシンプルなアルゴリズムを用意しました。
- n分平均が上昇(下降)に転じた時
- ある時点から価格がn%上昇(下降)した時
このいくつかのアルゴリズムを、以下のような独自の書式で「購入」「売却」毎に組み合わせて指定できるようにしました。
buy:three_average(3times)|sell:border_one_percentこの書式によってアルゴリズムが一意に特定できるので、売買結果履歴にこの文字列を含める事で、アルゴリズム毎の結果を分析できるようにしました。
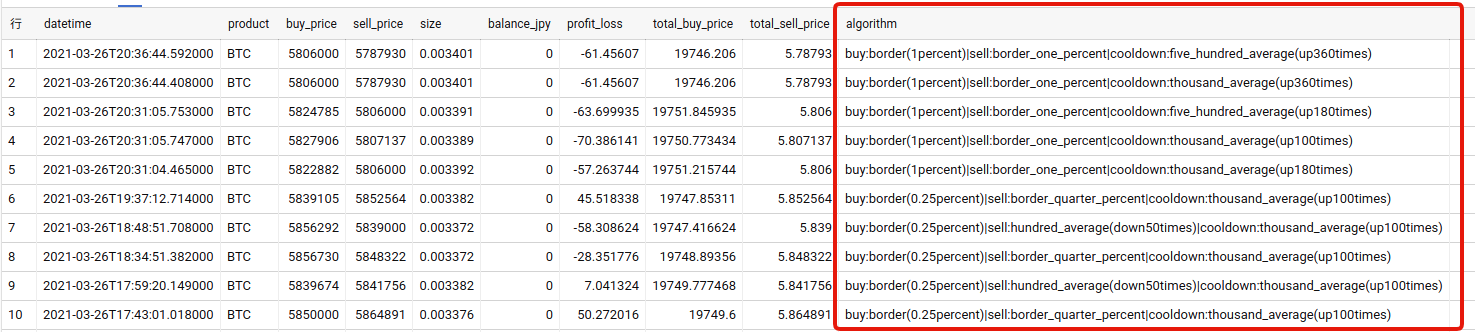
インフラの構築について
terraformを使用しました。

terraformとはインフラをコードで管理するためのツールです。
HCL(HashiCorp configuration language)と呼ばれる言語でインフラの構成を記述し、terraform applyを実行すると各種クラウドプラットフォーム上にインフラが構築されます。
以下は、BigQuery上にテーブルを作成している例です。
resource "google_bigquery_dataset" "prod" {
dataset_id = "prod"
location = "EU"
default_table_expiration_ms = null
access {
role = "WRITER"
user_by_email = google_service_account.default.email
}
access {
role = "OWNER"
user_by_email = "xxxx@example.com"
}
}
resource "google_bigquery_table" "foo_table" {
dataset_id = google_bigquery_dataset.prod.dataset_id
table_id = "foo_table"
time_partitioning {
type = "DAY"
field = "datetime"
expiration_ms = null
}
schema = file("./big_query_schemas/foo_table.json")
}
今回はこのterraformを使用して、ECSのタスクの定義からS3バケットの作成、BigQueryのテーブル定義まで全てコードで管理できるようにしました。
terraformは、複数のプラットフォームに跨って使用できるので、AWSとGCPのインフラをまとめて管理できるのが良いですね。
今回は以下3つの環境を用意しましたが、コード化した事により多くはコピペするだけで作成できました。
- テスト環境
- 効果測定環境
- 本番環境
Terraformについては、以下の書籍が「使い方」から「設計方針」、「ベストプラクティス」まで良くまとまっておりオススメです。

所感
DWHとBIを触りたかったので、いい勉強になりました。

Webエンジニアをやっています
UX/UIデザインからプログラミング、DB設計、SEO、インフラ構築など幅広く対応してます
PHP/PHPUnit/Laravel/Vue/Nuxt/Docker/Terraform
ご連絡はTwitterのDMまで。