
目次
今更ながらMySQLの全文検索インデックスを触ってみる事にした。
全文検索インデックスを貼る
ドキュメントを読むと日本語に対応した全文検索インデックスは以下の2種類あるらしい。
- Ngramパーサー
- MeCabフルテキストパーサープラグイン
今回はNgramパーサーを使う。
デフォルトでは2文字づつ区切る2-gram(バイグラム)が使用されるらしい。
以下の様なSQLでNgramパーサーのインデックスを作成できる
CREATE FULLTEXT INDEX items_description_fulltext ON items(description) WITH PARSER ngram;
テストデータを作成する
LaravelのSeeder, Factory, Fakerを駆使して100万レコードを生成する。
Fakerの言語をja_JPにする事で日本語のランダムなテキストを生成できる。
コードは以下の様な感じ。5000レコードづつバッファしながら挿入していく。
ちなみに100万レコードを挿入するだけで10分ぐらい掛かった。
$faker = Faker::create('ja_JP');
$buffer = [];
for ($i = 0; $i < 1000000; $i++) {
$item = [
/** 省略 **/
'name' => $faker->city,
'description' => $faker->realText,
/** 省略 **/
];
$buffer[] = $item;
if (count($buffer) == 5000) {
\Illuminate\Support\Facades\DB::table('items')->insert($buffer);
$buffer = [];
}
}

インデックスの内容を確認する。
普通のインデックスなら以下のSQLでサイズが確認できたりするのだが、全文検索は表示されなかった。
扱いが異なるらしい。
SELECT stat_value, index_name, (stat_value * @@innodb_page_size) / 1024 / 1024 AS size_mb FROM mysql.innodb_index_stats WHERE stat_name = 'size';
information_schemaのINNODB_TABLESテーブルをみると全文検索インデックス用のテーブルがいくつか作成されている事がわかる。(テーブル名がfts_から始まる物)
ただしこのテーブルを直接参照する事はできず、後述のinnodb_ft_aux_table変数を設定する事で間接的に確認できる。
SELECT * FROM information_schema.INNODB_TABLES;
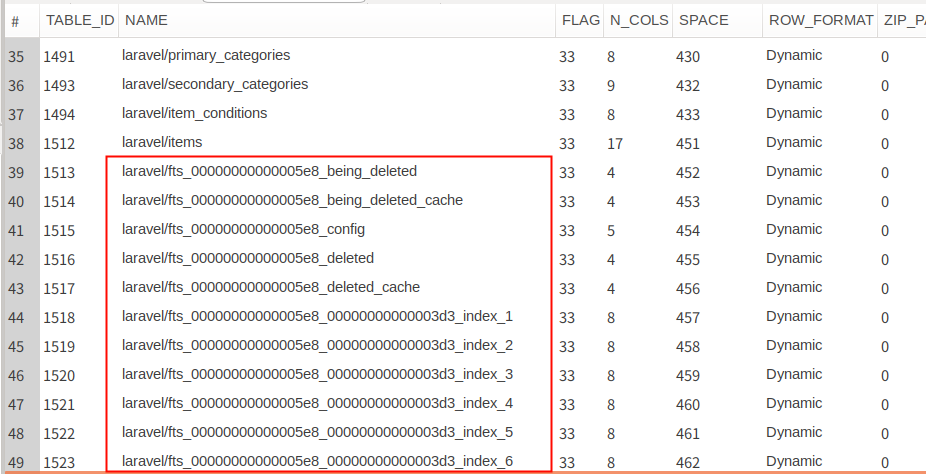
テーブルの内容を確認するには以下の手順を踏む必要がある。
内容を見ると、2-gramのインデックスなので2文字づつ格納されているのが分かる。
-- OPTIMIZE時に全文検索インデックスを再構築するフラグを立てる SET GLOBAL innodb_optimize_fulltext_only=ON; -- 全文検索インデックスを再構築する OPTIMIZE TABLE items; -- innodb_ft_aux_tableに全文検索インデックスが貼られているテーブルを指定する SET GLOBAL innodb_ft_aux_table = 'laravel/items'; -- インデックスの内容を確認する SELECT * FROM INFORMATION_SCHEMA.INNODB_FT_INDEX_TABLE LIMIT 15 OFFSET 70000;
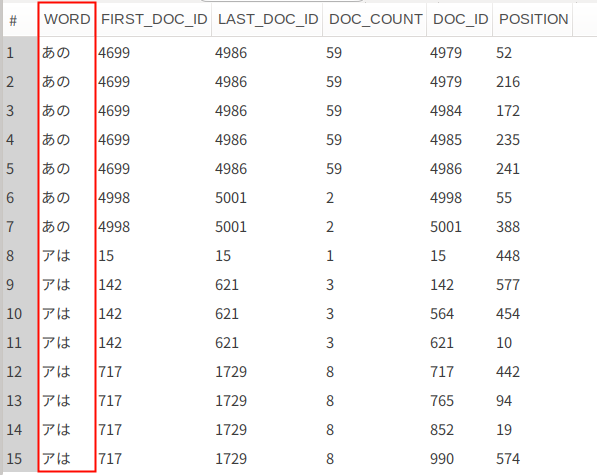
innodb_ft_aux_tableで指定したテーブルに貼られている全文検索インデックスの内容がINFORMATION_SCHEMAのINNODB_FT_***テーブルにロードされ、確認できる様になる。
全文検索してみる
検索クエリは以下の様にMATCH AGAINST 構文を使用する。

検索クエリは以下の3種類があり、それぞれ検索ワードの扱われ方が異なる。
- 自然言語検索 (
IN NATURAL LANGUAGE MODE)- 検索ワードをフレーズとして扱い、単語を抽出して検索を行う
- ブール検索(
IN BOOLEAN MODE)- 特殊な演算子を用いて複数の単語をAND検索やOR検索できる
- クエリ拡張検索(
WITH QUERY EXPANSION)- 自然言語検索の拡張版で、検索した結果を用いてもう一度検索するらしい。(よく分かっていない。)
ブール検索をやってみる。
SELECT * FROM items WHERE MATCH (description) AGAINST ('+シグナルやアスパラガスの葉' IN BOOLEAN MODE);
処理時間: 28.318s
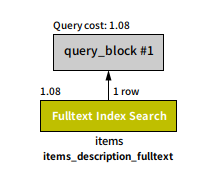
実行計画を見ると、全文検索インデックスが使われている様だが、処理時間が妙に長い。
何か間違っているのかもしれない。
調べた所、2-gramの全文検索インデックスを効かせるには以下の様に、検索ワードも2文字に分割する必要があるらしい。
SELECT * FROM items WHERE MATCH (description) AGAINST ('+シグ +グナ +ナル +ルや +やア +アス +スパ +パラ +ラガ +ガス +スの +の葉' IN BOOLEAN MODE);
処理時間:0.766s
処理時間が大幅に早くなった。
いちおうLIKE検索と比較してみる。
SELECT * FROM items WHERE description LIKE '%シグナルやアスパラガスの葉%';
処理時間:3.702s

当然ながらLIKE検索の方が5倍ほど遅い。
実行計画を見るともちろんテーブルフルスキャンになっている。
ちなみにLaravelのEloquent ModelでMATCH AGAINSTを書こうとするとこうなる。
BOOLEAN MODEの場合は更に特殊文字のエスケープも必要になる。
$query->whereRaw('MATCH (name,description) AGAINST (\'?\' IN BOOLEAN MODE', [$keyword]);
所感
特別なミドルウェアなどを用意する事なくお手軽に全文検索が出来る様になるので、無闇にシステムの構成要素を増やしたくないスタートアップやベンチャーのプロダクトで重宝するんじゃないかなぁと思います。

Webエンジニアをやっています
UX/UIデザインからプログラミング、DB設計、SEO、インフラ構築など幅広く対応してます
PHP/PHPUnit/Laravel/Vue/Nuxt/Docker/Terraform
ご連絡はTwitterのDMまで。